The data pipeline: Data science doesn't mean data science (Part 1)
This post comprises Part 1 of a 3-part series on data science in name, theory and practice.
When I first began delving into data science, I had trouble figuring out where to start. NoSQL databases, Hadoop, machine learning - these are buzzwords thrown around the community yet none of them serve as useful entry points for beginners. Today’s post is the one I wish I had read when taking my first steps into data science.
One of the most important steps when studying a new field is to understand the jargon - the disciplinary-specific terms which abstract from otherwise complex concepts. But the jargon does not come easy: starting at the wrong end of the complexity spectrum can have you, for example, tackling number theory before you’ve finished algebra. As a result, determining the order in which to learn the terminology must necessarily precede a comprehension of that terminology.
Though “data science” has easily been the most popular term emerging from the 21st century data-related fields, it is by far the least accessible. Instead, I believe the data field is more intuitively segmented into four closely related, first-order terms, which I will attempt to define:
- Data science: the implementation of advanced statistical concepts (eg. machine learning, Bayesian statistics, probability theory) primarily using modern software and (often big) data. As the engineer Josh Wills tweeted, data scientists are better statisticians than most programmers and better programmers than most statisticians.
- Data analysis: the analysis of business and research questions using database querying (eg. SQL), data wrangling, intermediate statistics, problem-solving skills, domain experience and a knack for seeing the big picture. Data analysts are generalists (like business analysts and management consultants) while data scientists are typically specialists (like mathematicians and statisticians).
- Data engineering: the extraction, validation and transformation of data, as well as the design of database architecture.
- Big data (related, though orthogonal): the use of distributed computing to analyze massive datasets which cannot be processed on a single workstation or server.
You’ll notice there’s currently no single term, no field of study, no academic department, which unifies these terms. And yet, they should be studied in unison: any project which gathers data and tests hypotheses necessitates them. Absent any overarching field name, a data practitioner must traverse nominally discrete fields, each of which imply a considerable degree of specialty.
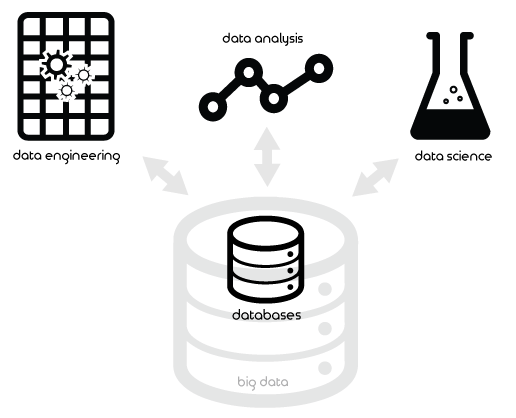
“Data science” is the most natural name for this field. Though fields like “information science” and “political science” are broad, “data science,” as it is popularly defined, is uniquely and unfortunately narrow. This is problematic because general fields typically serve as a roadmap for all subfields - a cursory glance at what they are and how they relate. “Data science” today does not provide this roadmap.
A general “data science” field has two properties which distinguishes it from other fields. The first is that its subfields all revolve around databases, or the storage of data (structured or unstructured). This means that data science is not so broad as to be the equivalent of information science, but rather a subset. Second, the subfields all offer methodologies and tools for applying the scientific method. For example, while something like data security is highly related to databases, it offers little use when analyzing business questions using data.

What happens to all of today’s “data scientists”? Surely, not everyone who works in the field of data science should suddenly carry a title reserved for statistical whizzes. Rather, today’s data scientists should be renamed; ”computational statisticians” or “statistical scientists” are two reasonable candidates. Frankly, “data” is far too broad a term to be restricted to advanced statistics.
Most importantly, “data science” - the field - becomes accessible. Studying data science no longer means starting with algorithms and probability, but rather more introductory topics like like gathering, storing, curating, validating, transforming, analyzing and visualizing data. “Data scientist” as a job title loses meaning, just as “computer scientist” or “information scientist” are too general to describe a job function. “Data scientist” no longer signifies a senior, elevated “data analyst,” but rather a fundamentally different career path. As a result, data analysts are no longer encouraged to pursue advanced statistics as the next step on their career path, but can instead branch out to a variety of specialties similar to their generalist counterparts in management consulting.
Despite the popularity of data science’s current usage, a redefinition of the term will clarify the field’s direction and establish the foundation for a coherent, organized taxonomy for all data-related disciplines.